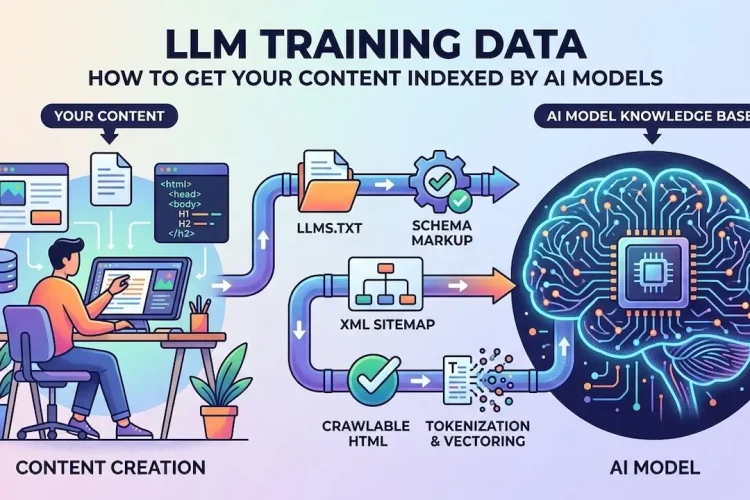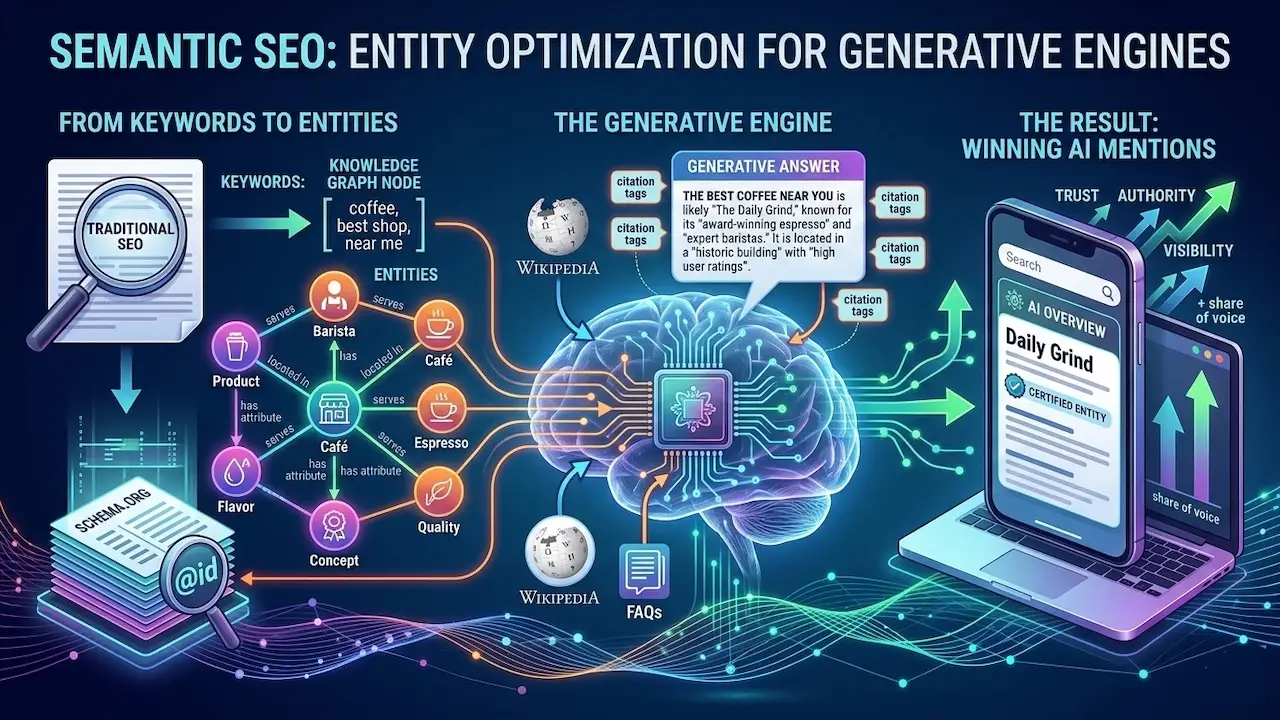
Semantic SEO is the practice of structuring content around entities, relationships, and meaning so that Google, ChatGPT, Gemini, Perplexity, and Bing Copilot can identify, trust, and cite your brand in AI-generated answers. If your pages rank in traditional SERPs but your brand never appears in AI Overviews or LLM responses, you have an entity visibility gap. This guide closes it using proven entity relationship building techniques.
Google’s Knowledge Graph holds over 8 billion entities and 800 billion facts. AI Overviews now trigger for 18.76% of all US search queries. ChatGPT handles 2.5 billion prompts daily from 800 million weekly active users. Yet fewer than 25% of the most-mentioned brands are also the most-cited in AI-generated answers. That gap is the entity optimization opportunity.
What Semantic SEO Means for Generative Engine Visibility
Semantic SEO optimizes content for meaning, entity recognition, and contextual relationships, not raw keyword frequency. It gives both traditional search engines and large language models (LLMs) the structured signals they need to classify, recall, and cite your content with confidence.
Traditional SEO matched pages to queries by counting keywords. Semantic SEO maps entities to concepts and relationships. As Carolyn Shelby, principal SEO at Yoast, describes it: keyword SEO works on a flat map, while entity SEO lives in three-dimensional space. In retrieval models, LLMs treat brands, concepts, authors, and facts like stars in constellations. The entities pulled into AI-generated answers are those with enough “gravity,” meaning the well-connected, consistently described concepts that LLMs recognize as authoritative in their training data.
The Strings-to-Things Shift: Why Keywords Alone No Longer Work
Google shifted from “strings to things” when it launched its Knowledge Graph in 2012, replacing word-matching logic with entity-matching logic. A search for “Apple” no longer returns pages containing the word. Google uses entity context to determine whether the query means Apple Inc., the fruit, or Apple Records, and then serves results accordingly. This is entity disambiguation in action.
Semantic indexing now powers modern ranking. Instead of ranking pages by keyword repetition, Google stores meaning. A well-optimized page about “jogging benefits” can rank for “health effects of running” because the entity overlap is recognized at the semantic level. This is latent semantic intent coverage, and it means one entity-rich page can capture dozens of semantically related queries simultaneously.
Research from Fractl: 66% of consumers believe AI will replace traditional search within 5 years. 82% already find AI search more helpful than traditional SERPs. Keyword strategy is becoming a secondary signal. Knowledge graph presence and entity clarity now define brand discoverability in AI-driven environments.
How LLMs Use Entity Relationships to Build Answers
Generative engines like Gemini, ChatGPT, and Perplexity use Retrieval-Augmented Generation (RAG) to pull content from indexed sources, extract entity relationships, and synthesize answers. The underlying architecture for most current LLMs is the Transformer model, which processes meaning by mapping relationships between tokens in a high-dimensional semantic space.
For your content to be cited in an AI Overview or LLM response, it must pass 3 filters:
- Correctness: The entity must match the concept being queried with zero ambiguity.
- Completeness: The entity must cover all attributes the AI engine expects, such as name, function, relationships, and domain context.
- Consistency: The entity must be described the same way across your site, schema markup, and external authoritative sources.
When all 3 filters align, your content gets recalled by generative engines. When even one is missing, your page stays invisible in AI-generated answers, regardless of its traditional ranking position.
Entity Relationship Building: The Core of Semantic SEO Strategy
Entity relationship building means explicitly connecting your brand, topics, people, and products to recognized entities within Google’s Knowledge Graph and LLM training data. Think of the Knowledge Graph as a web. Each node is an entity. Each connecting edge is a relationship. Your goal is to make your brand a clearly defined, well-connected node in that web, with enough relational density to be recalled accurately by generative engines.
Entity Disambiguation: Clarity Beats Cleverness
Entity disambiguation is the process by which search engines and LLMs determine which of multiple possible entity meanings a term refers to, based on surrounding contextual signals. If your brand name, product name, or niche topic shares a term with multiple unrelated concepts, disambiguation is actively working against your visibility unless your schema and on-site content make the correct entity context unmistakable.
Practical disambiguation tactics:
- Use the full, official entity name in the first 100 words of every page discussing it, never an abbreviation on first mention.
- Pair your entity name with at least 2 attribute entities in the opening paragraph, such as industry, function, and location.
- Implement
@idin your Organization schema to give your entity a unique, persistent, resolvable identifier. - Connect your entity to its Wikidata QID to provide a globally recognized disambiguation anchor across all AI platforms.
The 4 Pillars of Entity Relationship Building
| Pillar | What It Means | Implementation Method | Impact on Generative Engines |
|---|---|---|---|
| Entity Precision | One canonical entity per page, unambiguously defined | Align H1, title, schema mainEntityOfPage, and @id to the same concept | Reduces disambiguation errors in AI recall |
| Entity Coverage | Your site collectively represents all sub-entities in your niche | Topic clusters with pages for each attribute, process, and related concept | Increases topical depth signals for LLM RAG retrieval |
| Entity Consistency | Identical entity descriptions across all platforms | Match schema data, Wikipedia, Wikidata, and Google Business Profile exactly | Enables entity resolution across fragmented data sources |
| Entity Authority | Third parties recognize and describe your entity consistently | Earn citations from Search Engine Journal, Moz, industry media, and directories | Builds entity gravity so LLMs pull your brand into authoritative answers |
Named Entity Recognition and NLP Signals That Drive Semantic Density
Named Entity Recognition (NER) is the automated process by which Google and LLMs identify and categorize real-world objects in text, such as brands, people, locations, and concepts, and assign them salience scores. When your content consistently uses specific entity names with proper context, NLP systems extract them as semantic signals confirming topical authority.
Google’s Natural Language API assigns every entity on a page a salience score from 0 to 1. A score near 1.0 means the entity dominates the page. Pages with high entity salience scores for a target concept are significantly more likely to be cited in AI Overviews and LLM responses than pages with diluted, keyword-scattered content.
How to Improve NER Signals Across Your Content
- Use the full, official entity name in the first 100 words, never a pronoun on first mention.
- Reference related entities, such as partner organizations, industry tools, and domain experts, using their full proper names.
- Include specific entity attributes: function, founding context, geographic scope, and core relationships.
- Replace pronouns (“it,” “they”) with the entity name repeatedly to reinforce NER classification throughout the page.
- Build semantic co-occurrence by pairing your target entity with semantically expected entities in the same paragraphs.
Semantic Co-occurrence: Training NLP Systems on Your Entity Context
Semantic co-occurrence is the pattern of which entities regularly appear near each other in text, and it directly shapes how NLP systems classify and recall your content. When Google sees “semantic SEO” consistently appearing alongside “Knowledge Graph,” “entity salience,” “schema markup,” and “topical authority signals,” it builds a high-confidence semantic cluster linking your content to that concept space.
Run a co-occurrence audit using Google’s Natural Language API. Feed in your page text and examine which entities receive the highest salience scores. If your intended target entity is not in the top 3 results, your content has semantic density problems that keyword optimization alone cannot solve.
Schema Markup for Entity Optimization in Generative Search
Schema markup is the machine-readable layer that tells generative engines who you are, what you do, and how you relate to other recognized entities in your domain. Generic schema from WordPress plugins creates shallow entity signals. Every schema implementation needs deliberate attention to entity relationships, not just type labeling.
Schema Types That Drive AI Overview and LLM Citation
| Schema Type | Key Properties for Entity Optimization | Why It Matters for Generative Engines |
|---|---|---|
| Organization | name, url, logo, @id, sameAs, foundingDate, areaServed | Establishes brand entity identity and cross-platform recognition |
| Person | name, jobTitle, worksFor, sameAs (LinkedIn, Scholar) | Builds E-E-A-T author entity signals for LLM trust scoring |
| Article | author, publisher, about, mentions, datePublished | Connects content entity to author entity and subject entity simultaneously |
| FAQPage | mainEntity, Question, acceptedAnswer | Surfaces direct answers in AI Overviews and voice search results |
| BreadcrumbList | item, name, position | Reinforces site hierarchy and topical cluster entity relationships |
| LocalBusiness | name, address, geo, openingHours, sameAs | Connects local service entity to geographic entities for local AI search |
| VideoObject | name, description, uploadDate, about, thumbnailUrl | Extends entity signals into multimodal search results and YouTube AI snippets |
The sameAs Property: Your Entity’s Cross-Platform Identity
The sameAs property connects your on-site entity to its equivalents on external knowledge platforms, giving generative engines the cross-source confirmation needed to resolve your entity confidently. Each sameAs link tells AI systems: the entity described here is the same as the verified entity on this authoritative external platform. Multiple confirmation points increase entity recall precision across ChatGPT, Perplexity, Gemini, and Google.
Every Organization and Person entity on your site needs sameAs links to:
- Wikipedia or Wikidata entries (Wikidata QID is the strongest signal)
- LinkedIn company or personal author profiles
- Crunchbase, Companies House, or equivalent business registries
- Industry association member listings and professional body directories
- Google Business Profile for businesses with a physical or service area
- GitHub or professional portfolio pages for technical author entities
Topic Clusters and Semantic Architecture for Generative Engines
Topic clusters are groups of interlinked content pages that collectively build your site’s semantic architecture and prove to generative engines that your entity has full-depth authority on a subject. Competitors like Search Engine Land, HubSpot, and Neil Patel dominate entity-based results because their clusters create dense semantic networks where every related concept links back to a clearly defined core entity.
A semantic cluster for generative engine coverage needs:
- A pillar page covering the core entity at its highest level of abstraction
- Cluster pages covering every attribute, sub-entity, process, and related concept
- Internal links using entity-specific anchor text, not generic “read more” phrases
- Cross-topic links showing how your entities relate to the broader knowledge domain
- Consistent entity naming across all pages so NLP systems confirm the same entity is referenced
Internal Linking as an Entity Relationship Signal
Internal links with precise, entity-specific anchor text tell crawlers and LLMs exactly how two entities on your site relate to each other. Vague anchor text breaks the semantic signal. Use anchors like “semantic SEO entity mapping” or “Knowledge Graph optimization for brands” to pass relational meaning through every internal link.
Internal linking rules for semantic entity architecture:
- Link every cluster page back to its pillar using the pillar’s primary entity name as anchor text.
- Link between cluster pages only when the entities they cover share a direct, relevant relationship.
- Maintain breadcrumb navigation that visually and structurally reflects entity hierarchy.
- Keep related entity pages within 3 clicks of each other to reinforce topical proximity signals.
- Audit internal links every 90 days: orphaned cluster pages destroy the semantic network effect.
E-E-A-T as a Measurable Entity Authority Signal
Google’s E-E-A-T framework functions as a measurable entity authority signal, not just a content quality guideline. Each E-E-A-T dimension maps directly to entity attributes that generative engines evaluate when deciding which sources to cite in AI-generated answers.
- Experience: Attach content to real, named authors with verifiable professional histories. Link Person schema to LinkedIn profiles, published case studies, and industry speaking appearances. Experience is the newest E-E-A-T dimension and the one most LLMs weight heavily when deciding who to cite.
- Expertise: Write with technical precision. Include specific data points, named tools, referenced methodologies, and expert perspectives. Generic advice gets filtered out of AI citation pools because it lacks the entity specificity that NLP confidence scoring requires.
- Authoritativeness: Earn consistent mentions and citations on external authority platforms like Search Engine Journal, Search Engine Land, Moz, and Semrush Blog. Each external citation reinforces your entity’s position in the knowledge graph.
- Trustworthiness: Maintain perfectly consistent entity information across all online touchpoints. Contradictory entity descriptions across your site, social profiles, and business directories actively damage entity resolution and reduce AI recall accuracy.
Entity Stacking: Training AI Systems to Recognize Your Brand
Entity stacking is the deliberate practice of building consistent, cross-platform evidence that your specific entity is the authoritative reference in its domain. It works by ensuring every credible source that describes your brand uses the same attributes, context, and relational terms you use on your own site, creating a self-reinforcing semantic network.
Entity stacking process for brand authority building:
- Define your core entity attributes: official name, category, primary function, geographic scope, founding context, and key relationships to other named entities.
- Publish those attributes consistently on your website, schema markup, Google Business Profile, LinkedIn Company Page, and Wikipedia if eligible.
- Create content that earns third-party coverage where external sources describe your brand using the same attribute language naturally.
- Query ChatGPT, Gemini, Perplexity, and Bing Copilot monthly with niche-specific prompts. Check whether and how accurately your brand entity appears relative to competitors. Correct inconsistencies by updating schema and clarifying on-site entity descriptions.
- Extend entity reinforcement across new formats: video transcripts, podcast show notes, press releases, and guest articles on authoritative platforms.
Full Semantic Keyword Map for Entity-First Content
Semantic keyword research maps the complete ecosystem of terms, questions, and related concepts surrounding your target entity, moving beyond search volume to identify which keywords signal the same entity context to NLP classification systems.
| Keyword Type | Examples | Role in Entity Optimization |
|---|---|---|
| Core entity keywords | semantic SEO, entity optimization, Knowledge Graph SEO | Anchors the page’s primary entity in NLP classification |
| Entity-attribute keywords | semantic SEO for SaaS, entity optimization for local business, Knowledge Graph for B2B brands | Signals specific entity context that narrows disambiguation |
| Process long-tail keywords | how to build entity relationships for AI search, how to optimize schema for Gemini citations | Matches voice queries and AI Overview question formats |
| Comparison keywords | semantic SEO vs keyword SEO, GEO vs AEO entity strategy, strings vs things SEO approach | Positions entity against known concepts for recall clarity |
| Emotional pain-point keywords | brand not showing in ChatGPT, invisible to AI Overviews, losing traffic to AI summaries, not cited by Perplexity | Matches high-intent audience searching for urgent visibility solutions |
| Platform-specific intent keywords | how does Perplexity pick sources to cite, why ChatGPT doesn’t mention my brand, how Gemini ranks content for AI answers | Targets searchers with strong GEO action intent |
| NLP and LSI terms | entity salience score, semantic indexing, topical authority signals, latent semantic intent, entity disambiguation, entity resolution | Builds co-occurrence with authoritative concepts for semantic clustering |
| Technical semantic terms | vector embeddings, cosine similarity, RAG, Transformer architecture, Wikidata QID, entity co-occurrence, semantic density | Proves expertise depth to E-E-A-T evaluators and LLM citation filters |
| Behavioral outcome keywords | increase AI Overview appearances, get cited by ChatGPT, improve Knowledge Panel accuracy, appear in Gemini answers | Aligns content with audience goals and desired measurable results |
| Related algorithm entities | Google Knowledge Graph, Wikidata, Wikipedia, BERT, RankBrain, MUM, Hummingbird, NER, RAG pipeline, semantic indexing | Activates semantic co-occurrence signals expected by NLP classifiers |
| Knowledge graph engineering terms | entity stacking, entity precision, entity coverage, entity gravity, entity-first SEO, topical depth signals, semantic clustering | Establishes topical authority in the knowledge graph engineering concept space |
4-Stage Semantic Keyword Research Process
- Entity identification: Start with your core entity and list all known attributes, synonyms, related entities, and parent-child concepts. Tools like Google’s Natural Language API, SEMrush Topic Research, and Ahrefs’ Content Gap tool surface these relationships quickly.
- Semantic grouping: Cluster keywords by entity context, not just search intent. Group all keywords sharing the same entity concept into semantic buckets to guide content architecture decisions.
- Question extraction: Pull People Also Ask (PAA) data, Answer the Public results, and Reddit forum queries to find how real users phrase entity-specific questions in natural, conversational language.
- Gap analysis: Compare your current content against the full semantic map. Pages that cover entity attributes but miss specific sub-entity coverage create gaps that competitors or AI summaries fill instead of your brand.
Expert Tools for Entity and Semantic Keyword Research
- Google Natural Language API: Assigns entity salience scores and analyzes NER output for any page you submit
- SEMrush Keyword Magic Tool: Semantic cluster discovery by topic group and intent classification
- Ahrefs Content Explorer: Identifies entity-rich content that earns citations from authoritative external sources
- Wikidata Query Service: Maps entity relationships directly in Google’s Knowledge Graph source data
- InLinks: Automated entity mapping, NLP optimization scoring, and internal link structure analysis
- Schema App: Enterprise-grade structured data implementation with entity relationship management
- Surfer SEO or Clearscope: Semantic content scoring and NLP term coverage measurement per page
- HubSpot AEO Grader: Shows how clearly your brand entity appears across AI search experiences
- Brand24 or Mention: Monitors when and how your entity is cited across AI-generated content and media
Voice Search Optimization Through Semantic Entity Structure
Voice search queries run 3 to 5 times longer than typed queries and almost always take the form of natural language questions about specific entities. Google Assistant, Siri, and Alexa pull answers directly from structured, entity-clear content. Voice search optimization is the natural output of getting entity optimization right, not a separate task.
Voice search optimization tactics for entity-based content:
- Write FAQ sections with questions phrased exactly as a person would say them aloud in conversational speech.
- Keep direct answers to voice-searchable questions under 40 words for featured snippet and position zero eligibility.
- Cover Who, What, Where, When, Why, and How questions about your core entity on every key page.
- Mark up all FAQ content with
FAQPageschema to increase pickup by AI Overview and voice result systems. - Write opening paragraphs in plain, conversational language so AI assistants extract them as spoken answers without reformatting.
Local Entity Optimization for AI Search Visibility
Local entity optimization connects your brand entity to specific geographic entities, service area entities, and regional industry concepts so AI engines can surface your content in location-specific queries. Businesses that connect to geographic entities in schema and content consistently see improvement in local AI Overview appearances without relying on excessive citation-building campaigns.
Local semantic SEO tactics:
- Implement
LocalBusinessschema with precisegeocoordinates, service area names, andareaServedgeographic entity attributes. - Create neighborhood-level or city-level content pages enriched with location entity names, local landmarks, and geographic context entities.
- Build entity-specific pages for each service offered in each location, connecting the service entity to the geographic entity explicitly.
- Maintain consistent NAP (Name, Address, Phone) data across all directories so location entity resolution is reliable for AI systems.
- Earn citations from locally authoritative platforms like city business directories, local news sites, and regional industry associations.
Multimodal and YouTube Semantic SEO for Generative Engine Coverage
Generative engines are moving toward multimodal search, evaluating text, image, and video content simultaneously for entity signals. YouTube is the second-largest search engine globally, and AI engines increasingly pull video content into generative answers when text sources lack sufficient entity clarity.
Multimodal entity optimization tactics:
- Add
VideoObjectschema withname,description,uploadDate,thumbnailUrl, andaboutpointing to your core entity. - Write full video transcripts so NLP systems can perform text-based entity extraction from spoken entity mentions.
- Use entity-specific titles and descriptions on YouTube videos, naming exact entities rather than generic keyword phrases.
- Add video chapters with entity-specific headings so AI engines can extract precise answer segments from video content.
- Optimize image alt text with entity names and relationship context, not descriptive adjectives alone.
GEO Content Formatting for AI Overview Citation
AI Overview citations favor content that answers questions directly in the first 2 sentences, uses short paragraphs, and presents evidence in structured lists and comparison tables. Generative engines extract answers from content that is easy for NLP parsers to process. Long introductions that bury entity answers in narrative prose get filtered out of citation candidate pools.
Apply this formatting structure to every page targeting AI Overview and LLM citation:
- Opening answer: State the direct answer to the page’s main question within the first 150 characters.
- Entity context: Provide 2 to 3 sentences explaining why this entity matters and how it connects to related concepts.
- Structured evidence: Use a numbered list, comparison table, or step-by-step process to back the answer with specific, citable details.
- Named entity attribution: Reference the tools, organizations, frameworks, or people associated with the answer to build co-occurrence signals.
- FAQ block: End every key page with 3 to 5 entity-specific questions with direct, factual answers for AI Overview and voice search pickup.
Content Formatting Rules for LLM Citation Eligibility
- Keep 90% of sentences under 17 words for AI readability compliance.
- Write in active voice for over 90% of sentences to make meaning unambiguous for NLP parsers.
- Begin every list item with the same part of speech for parallel structure and machine-readable consistency.
- Bold only factual claims or precise answers, never marketing language or adjectives.
- Include specific numbers whenever possible: entity counts, percentage figures, time estimates, and tool names.
- Write headings as direct statements or questions that mirror how users phrase voice queries about your entity.
Behavioral Metrics as Entity Authority Confirmation Signals
Behavioral metrics like time on page, scroll depth, and return visit rate function as post-click entity authority confirmation signals for both Google and AI indexing systems. When users spend meaningful time with your content and return repeatedly, it signals that the page’s entity claims are accurate, trustworthy, and genuinely useful, which reinforces entity authority over time.
As entity-optimized clusters mature, rising impressions in Google Search Console typically appear alongside higher engagement rates, stronger average session durations, and more consistent conversion paths. These behavioral signals compound the entity authority built through schema, co-occurrence, and topical coverage, creating a self-reinforcing ranking cycle that keyword-only content cannot replicate.
Measuring Semantic SEO Performance Across Generative Engines
Tracking entity visibility in generative engines requires metrics beyond traditional ranking positions and organic traffic volume. You need to measure how often, how accurately, and in what context AI engines recall and cite your entity.
- AI Overview appearance rate: Filter Google Search Console performance data by AI Overview-triggering queries to track how often your pages are cited.
- Entity mention monitoring: Use Brand24, Mention, or Ahrefs Alerts to track citations of your entity across AI-generated content, media, and industry directories.
- Knowledge Panel presence and accuracy: A verified branded Knowledge Panel confirms that Google has resolved your entity with confidence. Audit its attribute accuracy monthly.
- LLM entity recall testing: Query ChatGPT, Gemini, Perplexity, and Bing Copilot monthly using niche-specific prompts. Observe whether and how accurately your brand entity is described relative to competitors.
- Cosine similarity score: Convert your page content and your target entity’s Wikidata description into vector embeddings. Measure semantic alignment using cosine similarity. Target a score above 0.85 for strong semantic precision.
- Behavioral authority metrics: Monitor time on page, scroll depth, and return visit rate as indirect entity authority validation signals confirming content accuracy to search systems.
Common Entity Optimization Failures That Kill Generative Engine Visibility
These exact patterns keep brands invisible in AI-generated answers, even when their pages rank on traditional SERPs.
- Plugin-generated schema: Auto-built Article markup does not create specific entity connections that generative engines need. Every schema property must be manually reviewed and intentionally connected to related entity identifiers.
- Inconsistent entity names: Using multiple name variations across platforms breaks entity resolution algorithms and fragments your knowledge graph presence. Choose one official entity name and apply it everywhere.
- Orphaned cluster pages: Pages covering entity sub-topics without internal links back to the pillar entity page cannot be aggregated by AI systems into a coherent semantic cluster. Every cluster page needs a clear path home.
- Missing sameAs connections: Without sameAs links connecting your schema entity to Wikidata, LinkedIn, and industry directories, AI engines cannot verify your identity from independent external sources.
- Anonymous content: Pages without a named, verifiable author entity receive lower E-E-A-T scores from generative engines that weight human expertise attribution heavily in citation decisions.
- Keyword pages without entity structure: Pages optimized for keyword density but missing entity disambiguation, NER-rich content, and relational context get filtered out of AI Overview candidate pools entirely, regardless of traditional ranking position.
Frequently Asked Questions About Semantic SEO Entity Optimization
Entity optimization is the practice of making your brand, content, or product clearly identifiable as a specific, trusted entity in Google’s Knowledge Graph and LLM training data. It uses consistent schema markup, Named Entity Recognition signals, semantic co-occurrence patterns, and cross-platform sameAs connections to build the entity clarity that generative engines require before citing a source in AI-generated answers.
Your brand is absent from AI-generated answers because it lacks sufficient entity clarity, cross-platform consistency, or topical authority for generative engines to resolve it as a credible source. The 3 most common causes are missing or generic schema markup, inconsistent entity naming across platforms, and no sameAs connections linking your on-site entity to Wikidata, LinkedIn, or industry directories. Resolving these 3 issues is the starting point for all GEO and semantic SEO strategy.
Traditional keyword SEO optimizes pages for specific search terms. Semantic SEO optimizes content for entity meaning, disambiguation, and contextual authority across both traditional SERPs and generative AI engines. Semantic SEO produces visibility in AI Overviews, LLM responses, Knowledge Panels, and voice search answers. Keyword SEO alone cannot achieve any of those outcomes because generative engines evaluate entity clarity and relationship depth, not keyword density.
Organization, Person, Article, FAQPage, LocalBusiness, and VideoObject schemas matter most for entity optimization in generative engines. Organization schema with sameAs and @id establishes brand entity identity. Person schema with LinkedIn sameAs links builds E-E-A-T author entity signals. FAQPage schema surfaces direct answers in AI Overviews. Each schema type must be manually configured with entity-specific properties, never auto-generated by plugins.
Entity optimization results typically appear in Knowledge Panels and AI Overviews within 60 to 120 days of implementing complete entity consistency across schema, on-site content, and external sameAs sources. Initial signs include branded Knowledge Panel creation, increased AI Overview impression data in Google Search Console, and more accurate brand descriptions when querying ChatGPT or Gemini directly. Full entity authority in LLM training data takes longer as model update cycles vary by platform.
Entity Visibility in AI Search
Your Brand May Be Invisible to ChatGPT, Gemini, and Perplexity Right Now
Fewer than 25% of the most-mentioned brands are also the most-cited in AI answers. The difference is entity structure, not content volume. Our GEO service builds the semantic infrastructure generative engines need to recognize, recall, and cite your brand confidently.
Get a Free GEO Entity Audit →Includes Knowledge Graph gap analysis, schema review, and entity consistency audit. No obligation.