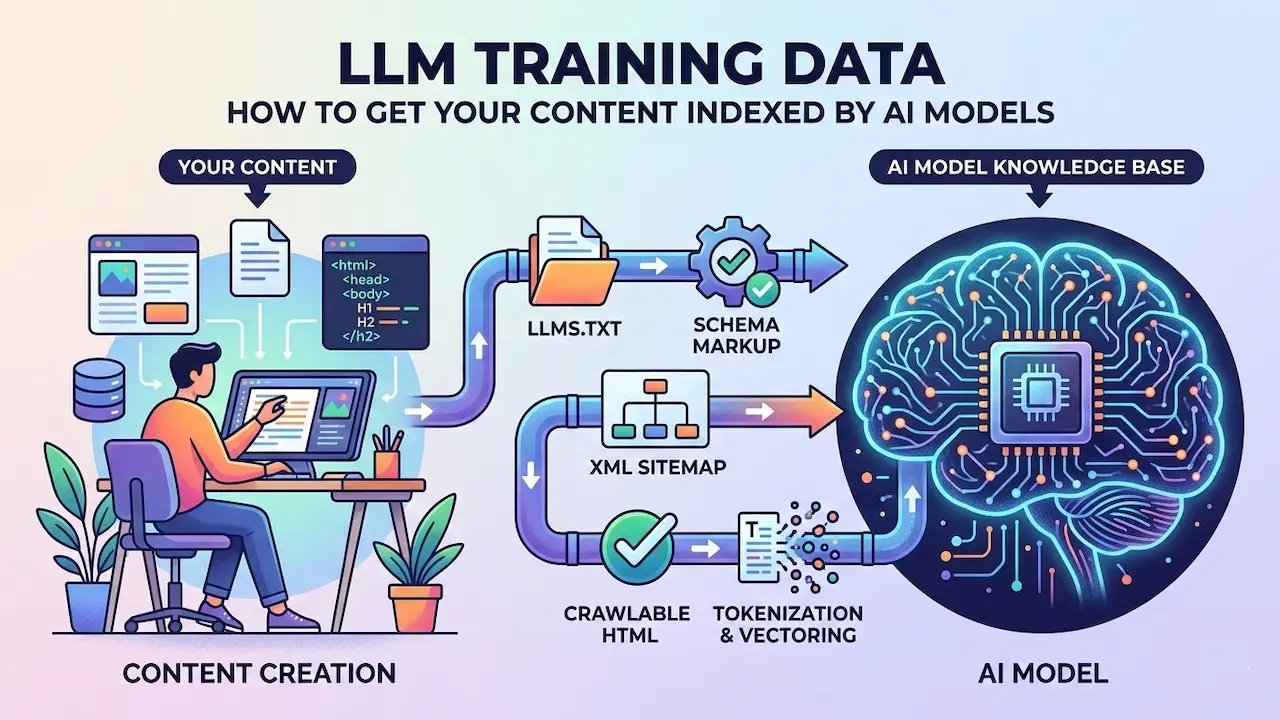
LLM training data is the text, code, and web content AI models train on. To get your content indexed by AI models, allow AI bots in robots.txt, add an llms.txt file, submit to Bing, add schema markup, and build citations on authoritative platforms. Miss one step and AI platforms skip your content entirely.
Brands losing customers to AI answers share one problem. Their content never entered the LLM training data pipeline. Competitors appearing in ChatGPT responses did not get there by accident. They fixed their AI crawl access. They submitted to Bing. And They built citations where training datasets already scrape. This guide gives you the exact same steps. Follow them to get found in Perplexity citations, appear in Gemini search results, and rank in AI-generated answers across every major platform.
What Is LLM Training Data?
LLM training data is the raw text corpus that AI models process during pre-training. Models learn language patterns, factual knowledge, and reasoning from this corpus. It spans trillions of tokens collected from the public web before any training run begins.
Your content influences two separate things. First, it shapes what a model knows during pre-training. Second, it determines what AI tools retrieve during live search queries. Both paths matter for AI model indexing. Most brands optimise for neither. That is why missing AI traffic is now the fastest-growing problem for content teams.
How Tokenization Turns Your Content Into AI Knowledge
Before training starts, raw text goes through tokenization. This breaks content into subword units called tokens. Models process tokens as numerical values stored in vector embeddings. These embeddings represent meaning relationships between concepts. Content with clear semantic chunking produces stronger vector embeddings. Stronger embeddings make your content more retrievable during live AI queries.
After pre-training, models go through supervised fine-tuning on curated instruction-response pairs. Then they go through RLHF, which stands for reinforcement learning from human feedback. This aligns model outputs with human preferences. Your content influences pre-training. Fine-tuning and RLHF happen on curated data after that stage.
The Named Datasets That Feed Every Major AI Model
AI developers rely on named, curated datasets. Knowing which datasets feed which models tells you where to place content to enter the AI training pipeline directly.
Common Crawl is the largest source. It collects petabytes of web pages across billions of domains every 4 to 8 weeks. GPT-4, Claude 3, LLaMA, Gemini, and Mistral all draw from it. Your site appears in Common Crawl only if AI bots can access your pages. A JavaScript rendering issue or a blocked bot cuts your domain out of every dataset built on Common Crawl.
Other Key Training Datasets
- C4 (Colossal Clean Crawled Corpus) is a filtered version of Common Crawl. It removes pages with low stop-word density and high symbol ratios. It trains T5, PaLM, and the Flan family.
- The Pile is 825 GB of text from 22 sources. It includes GitHub, PubMed, arXiv, and Stack Exchange. It trained GPT-NeoX and EleutherAI models.
- Dolma is a 3 trillion token corpus from Allen AI. It draws from Common Crawl, Wikipedia, GitHub, and Reddit. It trains the OLMo model series.
- RedPajama is an open reproduction of LLaMA’s training data. Community LLMs worldwide use it.
- Wikipedia appears in every major LLM corpus. A Wikipedia citation naming your brand carries outsized weight for AI model indexing.
- GitHub repositories with permissive licenses feed GPT-4, Claude, and Codex directly. Technical documentation on GitHub is a direct training data entry point.
Important: Common Crawl snapshots your domain every 4 to 8 weeks. Your window to enter the next AI training refresh is always open. Pages that pass quality filters in the next crawl can feed LLM training datasets within months.
How AI Model Indexing Actually Works
AI model indexing happens across two pipelines. The first is static pre-training data collection. The second is live retrieval-augmented generation, called RAG. Each pipeline runs on different rules. Each needs separate optimization actions.
Pipeline 1: Static Pre-Training Data Collection
AI developers harvest datasets from the public web before training begins. Crawlers including CCBot, GPTBot, and ClaudeBot collect raw pages. Those pages then pass through a quality filtering pipeline. Pages that fail any filter stage never reach tokenization.
The 5 Filters Every Page Must Pass
- Language detection removes non-target language pages
- MinHash deduplication collapses near-duplicate content into a single instance
- Perplexity scoring removes incoherent or machine-generated text
- Domain blocklisting filters known spam and low-authority domains at domain level
- Heuristic checks flag pages with low word counts or high symbol-to-word ratios
Blocking GPTBot or ClaudeBot hurts your AI visibility at the source. It removes that platform’s ability to collect your content permanently for that crawl period. No submission tool exists to recover those missed crawls after the fact.
Pipeline 2: Live RAG Retrieval
RAG is how AI search tools pull your content at query time. The AI queries a live index, retrieves top results, and synthesizes a response. Your search ranking determines whether your content gets retrieved at all.
RAG systems like LlamaIndex retrieve content through vector similarity search. They query databases like Pinecone, Weaviate, and Chroma. Content chunked into clean semantic passages retrieves more accurately. Passage-level clarity directly affects how often AI systems cite your content versus skipping it.
Why Bing Ranking Is Now an AI Citation Signal
For most non-Google AI platforms, Bing is the primary RAG source. Perplexity uses Bing. Microsoft Copilot uses Bing. ChatGPT Browse pulls from Bing via OpenAI’s web plugin. A page absent from Bing’s index is invisible to all three simultaneously. Most brands have never optimised a single page for Bing. That is the core reason AI ignores their websites despite strong Google rankings.
- Pre-training entry: requires open AI bots, clean HTML, and passing quality filters
- RAG retrieval entry: requires Bing and Google organic ranking positions
- Time to pre-training visibility: weeks to months depending on the next training run
- Time to RAG visibility: days to weeks via IndexNow submission to Bing
How to Get Your Content Into LLM Training Data
Getting content into LLM training data starts with removing technical barriers. Then you build authority signals. Apply these steps in order. Each one removes a blocker that stops the next from working.
Step 1: Open AI Crawlers in Your robots.txt
Many sites block AI bots through legacy wildcard rules. Check your robots.txt file today. Add explicit allow rules for each named AI crawler. Also set X-Robots-Tag: all in your server HTTP headers. Some bots read headers instead of the robots.txt file.
Check your server access logs 14 days after this change. Look for visits from GPTBot, ClaudeBot, CCBot, and PerplexityBot. No bot visits after 30 days means a deeper technical block exists. Fix crawl access before any other optimization step.
Step 2: Create Your llms.txt File
Jeremy Howard of Answer.AI introduced the llms.txt standard in September 2024. Place a Markdown file at yourdomain.com/llms.txt. It tells AI crawlers which pages to read, what your site covers, and which content to attribute to your brand. Also create an llms-full.txt version with full page text. Models with longer context windows use this version.
OpenAI and Perplexity already recognise this file. Most competitors have not deployed one yet. That gap is your competitive advantage in AI search today.
Step 3: Submit to Bing and Activate IndexNow
Register your site in Bing Webmaster Tools today. Submit your XML sitemap directly inside the tool. Bing feeds ChatGPT Browse, Microsoft Copilot, and Perplexity AI simultaneously. Sites in Bing Webmaster Tools get AI citations 3 to 4 weeks faster than sites relying on organic crawling.
Activate IndexNow after submitting your sitemap. IndexNow pings Bing within hours of each new page you publish. WordPress users activate it through Rank Math or Yoast SEO. No custom code is needed. Faster Bing indexing directly reduces missing AI traffic from Copilot, Perplexity, and ChatGPT Browse at once.
Also Submit to Google Search Console
Google AI Overviews pull from Google’s own index only. Submit your sitemap in Google Search Console separately. Use the URL Inspection tool to request indexing for priority pages. Strong Google ranking is the baseline requirement for Google AI Overview citations.
Step 4: Add JSON-LD Schema Markup
Pages with schema markup get cited in AI responses 3x more often than unstructured pages. Schema gives LLMs machine-readable signals before they process your body text. Add these schema types to key pages:
- Article schema on all blog posts and guides
- FAQPage schema on every FAQ section, with answers under 40 words each
- HowTo schema on all step-by-step guides
- Organization schema on your homepage with your full name, URL, and logo
FAQPage schema with sub-40-word answers is the most direct path for getting Google AI Overview to cite your site. It is also the primary voice search citation trigger. Google Assistant, Siri, and Alexa extract passages under 40 words and speak them aloud. This single schema type improves Google AI Overview presence, voice search citations, and People Also Ask appearances simultaneously.
Step 5: Build Citations on Authoritative Platforms
Wikipedia, GitHub, Stack Overflow, Medium, Reddit, and PR Newswire feed LLM training data directly. These platforms carry pre-verified authority status in quality filtering pipelines. Content cited on them enters training datasets at a higher rate than content on your own domain alone.
- Publish original research and cite your domain as the primary source
- Contribute factual content to relevant Wikipedia articles with your site as a reference
- Release technical documentation or open-source tools on GitHub with permissive licenses
- Earn brand mentions in press coverage on publications that LLM training datasets already trust
Each of these actions places your content inside source types that knowledge graph enrichment processes use during model training. These citations also survive MinHash deduplication because they appear on high-authority domains that pre-pass domain-level quality filters.
Build E-E-A-T Signals Alongside Platform Citations
LLM quality filters assess domain trust using expertise, experience, authoritativeness, and trustworthiness signals. Add author bio pages with verifiable credentials. Link to primary sources throughout your content. Display your organization registration details. Publish case studies with measurable outcomes and real client data. E-E-A-T improvements strengthen both the pre-training pipeline and RAG retrieval ranking from a single content investment.
Step 6: Fix JavaScript Rendering
AI crawlers cannot read content that appears only after client-side JavaScript runs. If your pages render through React, Vue, or Angular without server-side rendering, LLM bots receive an empty HTML shell. Use server-side rendering, static site generation, or Prerender.io to deliver complete HTML on the first bot request.
A page that renders perfectly in a browser but serves an empty shell to CCBot never enters Common Crawl’s dataset. JavaScript rendering problems are the most common cause of missing AI traffic on sites with strong content and good domain authority. Fix rendering before reviewing content quality.
Step 7: Publish Original Content That Passes Deduplication
MinHash deduplication collapses near-duplicate content before training begins. Content that mirrors existing sources too closely gets removed from the corpus entirely. Rephrasing a competitor’s article rarely works. The vector similarity remains high enough for deduplication filters to treat it as a duplicate instance.
Publish proprietary survey data, original research, or unique case studies with real outcomes. Give each piece a perspective not available elsewhere. Each original piece becomes an independent source in the pre-training corpus with its own vector embedding. This is the content approach that produces compounding AI visibility over time. It is the foundation of a future-proof content strategy that does not depend on algorithm updates to maintain AI citation presence.
Voice Search Tip: Format FAQ answers as complete sentences between 20 and 40 words. Answers in this range read naturally when spoken aloud. Google Assistant, Siri, and Alexa extract passages in this length when selecting a spoken response from web content.
Content Format That LLMs Prefer to Index
LLMs extract information at the passage level through semantic chunking. They pull individual sentences and short sections that directly answer specific queries. Your format determines how cleanly those passages extract. Poor format means AI systems skip your content even when they can access it.
Page Structure for Maximum Passage Extraction
- Put a direct factual answer in the first 300 characters of every page, before any background content
- Write H2 headings as natural language questions, such as “How does LLM training data indexing work?” rather than “Overview”
- Keep one idea per paragraph at 2 to 3 sentences maximum so extraction tools isolate each point cleanly
- Use numbered steps for any process with a sequence so AI models reconstruct ordered flows accurately
- Add FAQ sections with schema-tagged answers under 40 words each
- Place subheadings at least every 300 words to support both AI extraction and human readability
Writing Style That Passes AI Quality Filters
- Keep sentences under 17 words for the majority of body content
- Write in active voice in over 91% of sentences to pass readability scoring in filtering pipelines
- Use plain language a non-specialist reads and understands on the first pass
- Include specific numbers, named tools, and named organizations throughout the content
- Maintain consistent terminology across all pages so entity disambiguation tools link every mention to your brand correctly
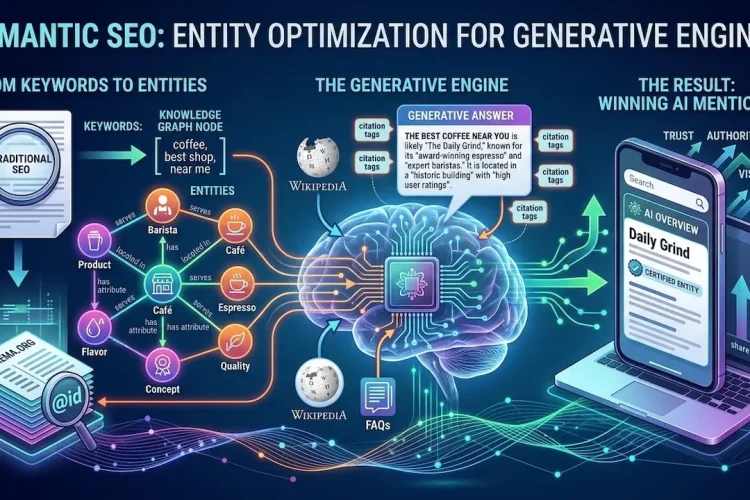
Entity Signals That Build Topical Authority
AI models understand topics through named entity recognition and vector embeddings, not keyword matching. Content that references the full entity landscape of a topic signals topical authority to both LLMs and traditional search algorithms at the same time.
For LLM training data as a topic, the entity field includes AI organizations like OpenAI, Anthropic, Google DeepMind, Meta AI, Mistral AI, Allen AI, and Hugging Face. It includes training datasets like Common Crawl, C4, The Pile, Dolma, and RedPajama. It includes training processes like RLHF, supervised fine-tuning, and instruction tuning. Also It includes retrieval tools like LlamaIndex, Pinecone, Weaviate, and Chroma. It includes AI visibility monitoring platforms like Indexly, Rankio, and Otterly.ai.
Why Entity Coverage Beats Keyword Density
Referencing these entities naturally within factual context demonstrates deep domain knowledge. AI quality filters reward this with higher training data inclusion rates. Traditional search algorithms reward it with stronger topical authority signals. One investment in entity-rich content improves rankings across Google, Bing, and AI retrieval platforms simultaneously. That is the practical difference between a future-proof content strategy and content that stops working when ranking signals shift.
GEO, AEO, and LLMO: The Three AI Visibility Disciplines
Three disciplines now work alongside traditional SEO for AI visibility. Each targets a different part of the pipeline. Brands that drop any one lose citations that competitors collect immediately.
What Is GEO (Generative Engine Optimization)?
GEO focuses on getting your brand cited inside AI-generated answers. Its outcome is brand mentions and citations inside ChatGPT, Perplexity, Gemini, and Claude responses. Users get your brand’s answer without clicking any traditional search result link. GEO works through structured content, third-party platform authority, schema implementation, and the llms.txt standard working together.
What Is AEO (Answer Engine Optimization)?
AEO structures content so AI systems extract it as a direct factual answer. Its outcome is appearing in zero-click AI answers, voice search results, and People Also Ask boxes. Getting Google AI Overview to cite your site through AEO requires FAQPage schema, a direct answer in your first paragraph, and question-format H2 headings. These same signals feed voice search extraction. AEO is the single optimization that improves Google AI Overview citations, voice search presence, and People Also Ask appearances from one content investment.
What Is LLMO (Large Language Model Optimization)?
LLMO makes content readable and authoritative enough to enter LLM pre-training corpora directly. Its outcome is shaping model knowledge long term through knowledge graph enrichment during training. LLMO works through original content that survives MinHash deduplication, open AI bot access, Common Crawl presence, and domain authority signals that pass all pre-training quality filter stages.
How All Four Work Together
SEO feeds RAG retrieval through Bing and Google ranking. GEO builds citation presence inside AI answers. AEO structures content for direct passage extraction as a spoken or displayed fact. LLMO gets content into the training corpus through tokenization, byte pair encoding, and vector embedding during pre-training. All four work in parallel. Dropping any one creates a gap competitors fill within weeks.
How to Track AI Indexing Activity on Your Site
No single dashboard shows AI indexing status like Google Search Console shows Google indexing. Run four tracking methods in parallel to identify where missing AI traffic originates and what to fix first.
Server Access Log Analysis
Filter server logs for visits from GPTBot, ClaudeBot, CCBot, Google-Extended, OAI-SearchBot, and PerplexityBot. Regular bot visits on key pages confirm active crawling. No visits after 30 days signals a technical block. Fix crawl access before reviewing content. Content bots cannot reach produces zero training data entry potential regardless of how well it is written.
Bing Webmaster Tools Indexing Reports
Bing Webmaster Tools shows which pages are indexed, crawled, and flagged for errors. A page absent from Bing’s index is invisible to ChatGPT Browse, Copilot, and Perplexity simultaneously. Check your most important pages weekly. Bing indexing gaps are the most overlooked cause of missing AI traffic for brands that rank well on Google but get zero AI citations.
Manual AI Platform Testing
Ask ChatGPT, Claude, Perplexity, and Gemini direct questions about topics your content covers. Note which sources each platform cites. If competitors appear consistently and your site does not, start with crawl access and Bing indexing steps first. Content quality is rarely the root cause of missing AI citations. Technical barriers are.
Dedicated LLM Visibility Tracking Tools
Indexly, Rankio, and Otterly.ai track AI citations and bot activity across major LLM platforms. They show which pages AI tools reference, where your brand appears in AI-generated answers, and which competitors get cited over you across ChatGPT, Perplexity, Claude, and Gemini. They also surface which pages fail AI crawl accessibility checks. Use their output to build a prioritised technical fix list ranked by citation impact.
Frequently Asked Questions About LLM Training Data
LLM training data is the text corpus AI models process during pre-training to learn language, facts, and reasoning through tokenization and vector embedding. It comes from Common Crawl, Wikipedia, GitHub, arXiv, PubMed, Reddit, and Stack Overflow. Cleaned versions like C4, Dolma, RedPajama, and The Pile train specific model families after applying MinHash deduplication, perplexity filtering, and heuristic quality scoring to raw crawl data.
Allow GPTBot and ClaudeBot in robots.txt, add an llms.txt file, and publish original content on pages that serve full HTML without JavaScript dependencies. Submit your sitemap to Bing Webmaster Tools and use IndexNow. Add JSON-LD schema markup. Build citations on Wikipedia, GitHub, and authoritative publications. Publish original research that passes MinHash deduplication as an independent source in the pre-training corpus.
Strong Google ranking is the baseline requirement for Google AI Overview citations. Beyond ranking, add FAQPage schema with answers under 40 words. Write a direct factual answer in your first paragraph. Use question-format H2 headings. These signals tell Google’s AI Overview system your page contains a clean, extractable answer rather than general topic coverage.
Yes, blocking GPTBot removes OpenAI’s ability to collect your content for ChatGPT training data and browsing retrieval permanently for that crawl period. Blocking ClaudeBot removes Anthropic’s access. Blocking Google-Extended removes Google’s access for Gemini and AI Overviews. No submission tool exists to recover missed crawls retroactively.
Google ranking and AI model indexing use different criteria across separate pipelines. AI models prioritize structured content, entity clarity, schema markup, original content that passes MinHash deduplication, and presence in Bing’s index for RAG retrieval. Sites ranking page 1 on Google fail AI quality filters because of JavaScript rendering issues, blocked AI bots, content too similar to existing sources, or absence from Bing’s index. Fix those technical barriers before reviewing content quality.